What's a code location?
We’ve talked a lot about definitions, but what about code locations? How do these two things work together?
A code location is a collection of Dagster definitions, such as assets. In Dagster, a code location is made up of two components:
- A Python module that contains a
Definitionsobject - A Python environment that can load the module above
Let’s go back to our cookie example for a moment. Cookies are typically baked in a kitchen, containing everything you need to make cookies. In the previous section, we talked about how your cookie assets (ex: dry ingredients, chocolate chip cookies) can be thought of as definitions.
To simplify baking, you would group everything you need in a single location. In this example, a kitchen functions much in the same way a code location does - it collects all of your Dagster definitions into a single location:
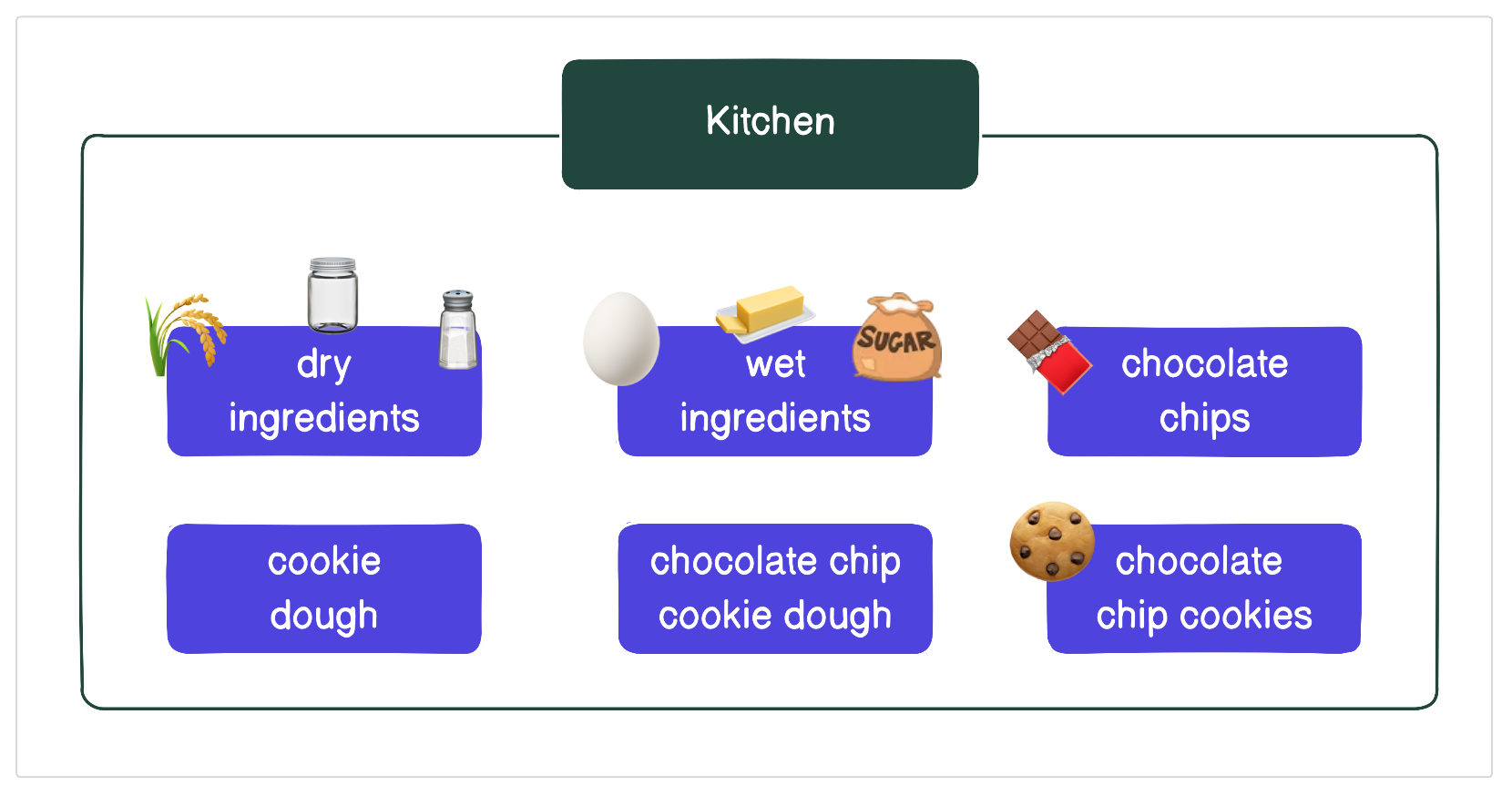
How are code locations helpful?
In software engineering, deployment is the mechanism by which applications are made available to end users. A Dagster deployment, for example, would include everything needed to run Dagster, such as Python, packages like pandas, the Dagster UI, etc. and make it available in a robust environment within the cloud.
Code locations exist to solve issues that come as Dagster deployments scale. When your organization grows to multiple teams orchestrating their data, things can become complicated with a single deployment.
Traditionally, this created problems such as:
- One team deploying their changes creates downtime for another team
- Two machine learning models use two different versions of the same Python package
- Being stuck using an old version of an orchestrator because your newer code uses the same dependency as your orchestrator
- Multiple teams contributing thousands of assets, making the UI difficult to search and navigate
Historically, many teams have tried multiple deployments to solve these problems. However, this creates silos in an organization and goes against being a “single pane of glass” of a company’s data assets. Multiple deployments can also lead to additional complexity, such as more complicated infrastructure, access management, and upgrades.
Dagster uses code locations to solve these problems. With code locations, users isolate their codebases without requiring multiple deployments.
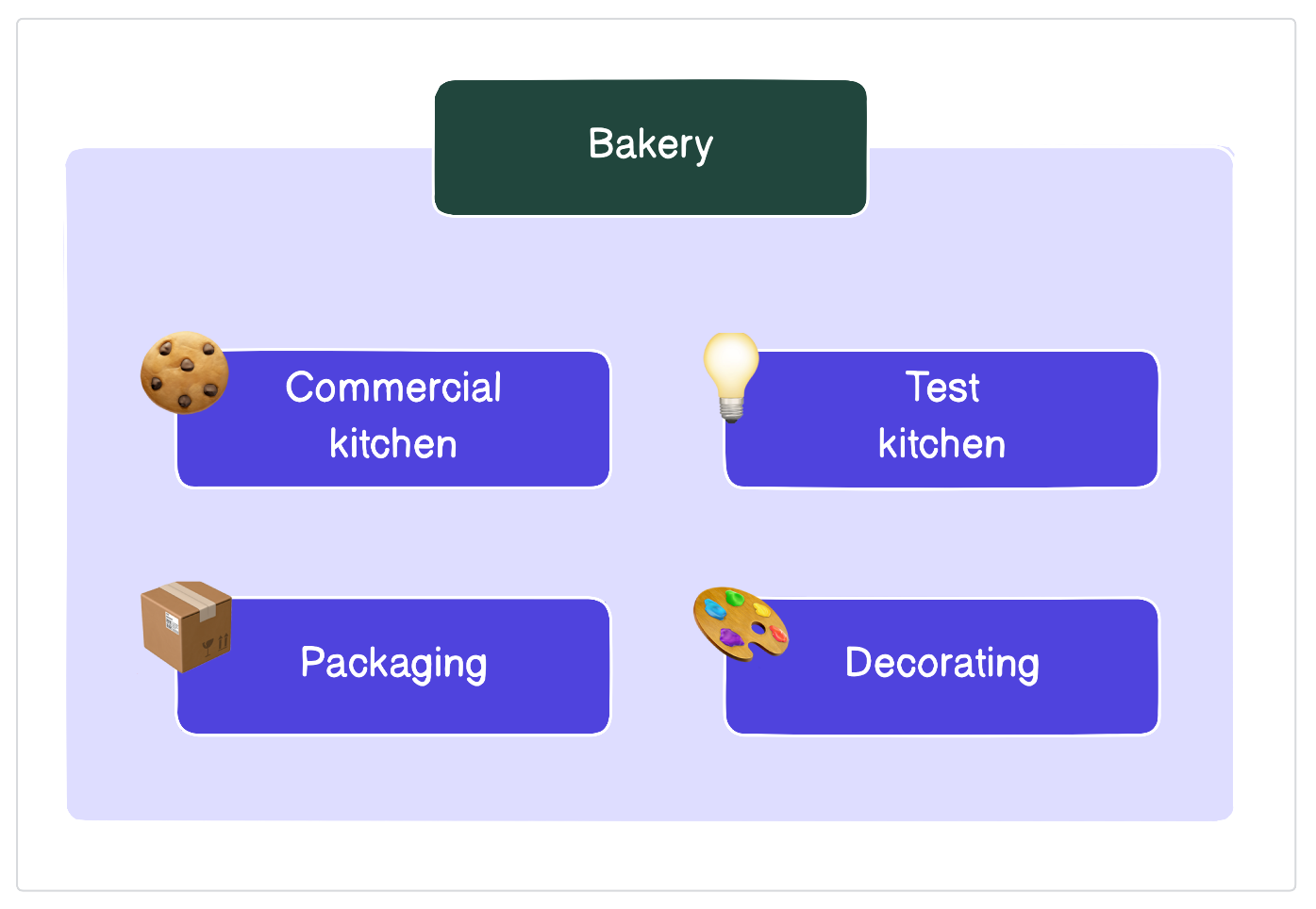
Let’s go back to the cookies for a moment. If your home cookie baking takes off, you might want to expand to becoming a fully-fledged bakery. In the real world, this could be a deployment of Dagster.
As you expand, you may use a kitchen for different purposes:
- A test kitchen
- Packaging
- Decorating
To ensure things run smoothly, you’d want each purpose to have its own location in the bakery. By giving each purpose its own location, you reduce the likelihood of locations negatively impacting each other. For example, a fire in the test kitchen wouldn’t impact the core business in the commercial kitchen.
However, despite all locations being independent of each other, they’re still in the same building. This allows you to always know what’s happening with all aspects of your bakery.
How does this relate to code locations in Dagster?
In the following image, each dark purple box is a code location. By separating code locations from the core Dagster services, user-deployed code is secure and isolated from the rest of Dagster. Code locations enable users to run code with their own versions of Python or dependencies.
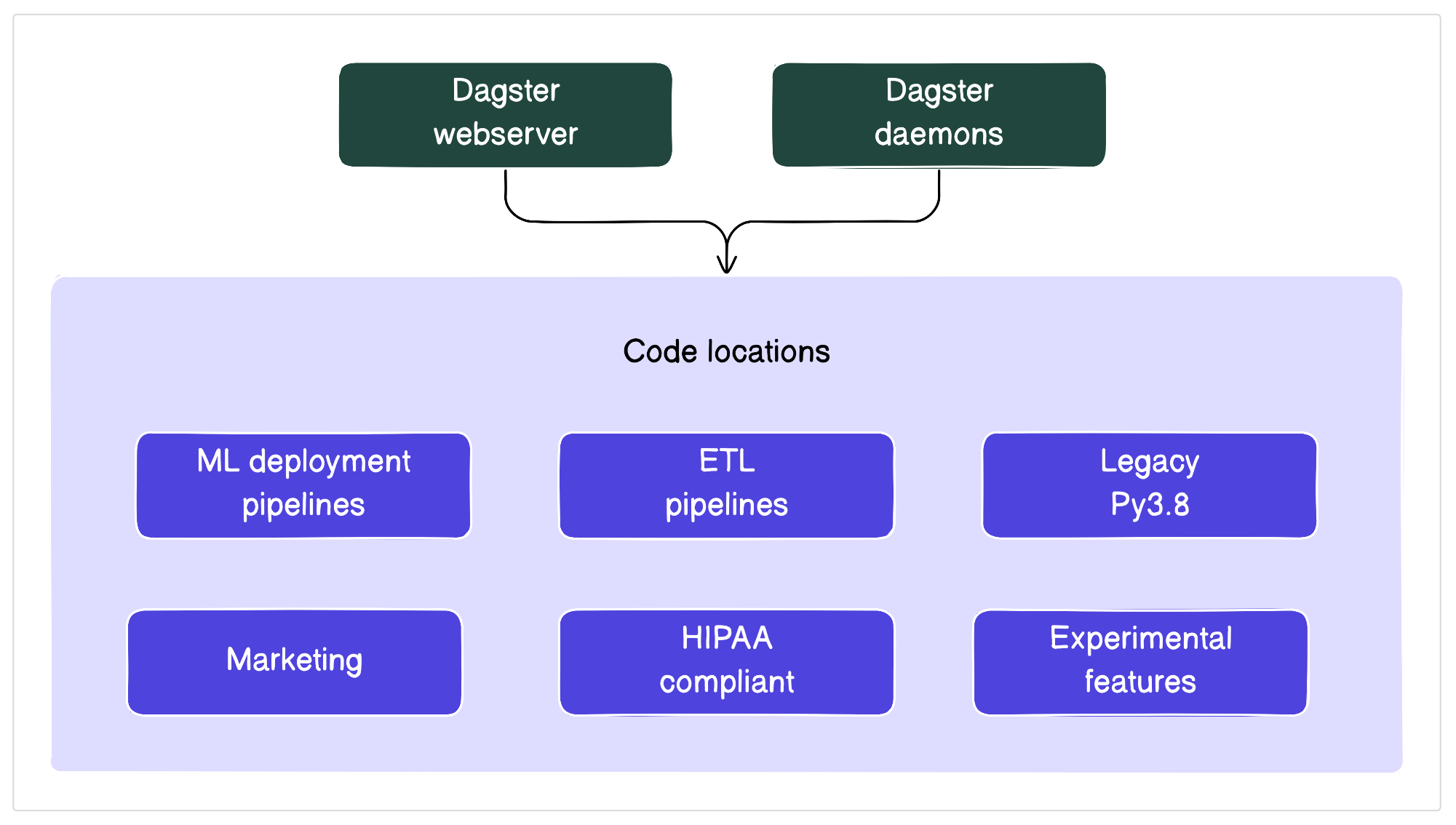
Code locations can be used to separate code by categories, such as:
- Teams (ex., marketing or product)
- Python version (ex., legacy code using Python 3.8 and newer Python 3.11 code locations)
- Dependency versions (ex., one model using PyTorch v1 and another using PyTorch v2)
These code locations are all maintained in one single Dagster deployment, and changes made to one code location won’t lead to downtime in another one. This allows you to silo packages and versions, but still create connections between data assets as needed. For example, an asset in one code location can depend on an asset in another code location.